Overview
Many people who are blind or have low vision access information about their surroundings and depicted in visual media through natural language descriptions of the images and video. A challenge is how to author image descriptions so that they are useful. Most efforts focus on how to produce one-size-fits-all descriptions for digital images. While this is a worthy goal, different people want different things in different situations, and as a result, it is challenging to find a single description that works for every user and context.
My goal is to identify the different contextual factors that impact what information people who are blind want to know about their surroundings and the images and videos they capture to train of vision-to-language and visual-question-answering algorithms.
This work is funded through a Bullard Postdoctoral Fellowship and a grant from Microsoft Research.
Keywords
blind, computer vision, context-aware, image caption, image description, low vision, multimodal analytics, user-centered data science, vision-to language, visual assistance, visual impairment, voice user interaction.
Responsive Image Descriptions According to One’s Information Goals
Responsive Image Descriptions According to the Source of an Image
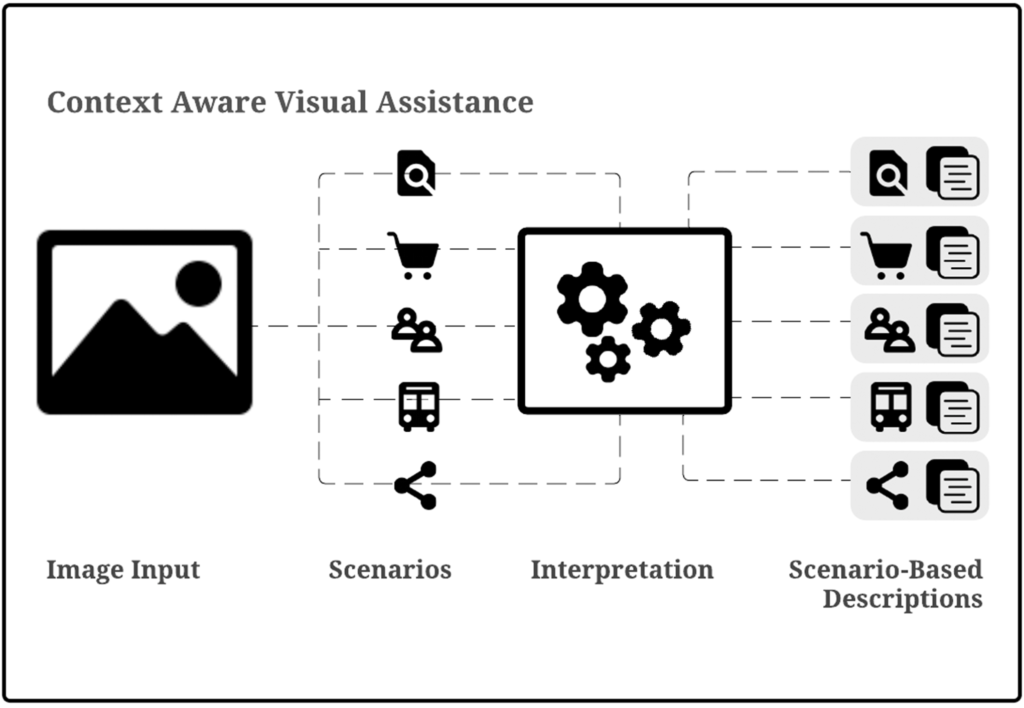
Responsive Image Descriptions According to One’s Visual Experience
VizWiz Dataset and Grand Challenge
Computer Vision for Accessible Shopping
Publications
Stangl, A., Morris, M. R., & Gurari, D. (2020) “Person, Shoes, Tree. Is the Person Naked?” What People with Vision Impairments Want in Image Descriptions. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems. ACM. (CHI), April, 2020.
Stangl, A., Kothari, E., Jain, S. D., Yeh, T., Grauman, K., & Gurari, D. (2018). BrowseWithMe: An Online Clothes Shopping Assistant for People with Visual Impairments. In Proceedings of the 20th International ACM SIGACCESS Conference on Computers and Accessibility (pp. 107-118). ACM.
Gurari, D., Li, Q., Stangl, A. , Guo, A., Lin, C., Grauman, K., … & Bigham, J. P. (2018). VizWiz Grand Challenge: Answering Visual Questions from Blind People. arXiv preprint arXiv:1802.08218.
Aim: My goal is to identify the different contextual factors that impact what information people who are blind want to know about their surroundings and the images and videos they capture. My hope is that findings from this research will be used to train of vision-to-language and visual-question-answering algorithms, and so AI-powered visual assistance technologies and voice user interfaces (that deliver context-aware verbal descriptions).
Approach: I conduct interviews and participatory design with people who are blind to learn about what information they want to be included in image descriptions, the situations in which they want a minimum viable image description vs. context-aware descriptions, and their non-visual information searching practices. I work in close collaboration with computer vision researchers and visual assistance technology users to inform my work.
Contribution: This work makes novel contributes to scholarship on User-Centered Data Science, Accessible AI, Computer Vision, Access Computing, and Human Computer Interaction. Developers can draw on my findings to curate user-centered datasets and train visual assistance technologies and voice user interfaces.